LLMForEverybody
(也许是)全网最全的神经网络优化器optimizer总结
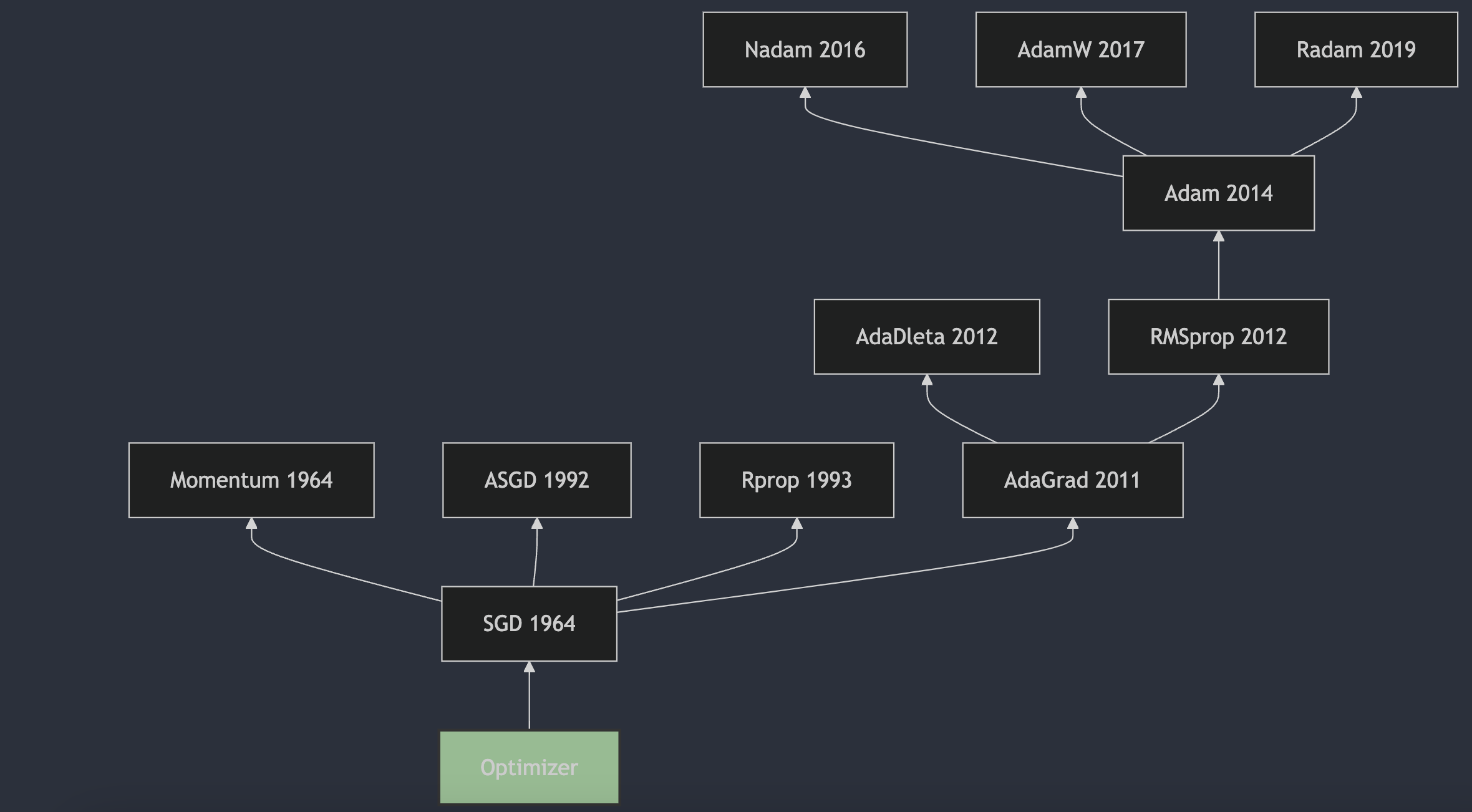
前一段时间,我想搞清楚优化器的发展脉络,试图了解从梯度下降到现在最常用的AdamW的发展。但搜索了很多资料,都没找到一个全面的总结。所以我决定自己整理一份,希望能帮助到大家。
optimizer负责在训练过程中更新模型的参数, 目的是通过调整参数来最小化损失函数,即模型预测和实际数据之间的差异.
文章链接
从1951年Herbert Robbins和Sutton Monro在其题为“随机近似方法”的文章中提出SGD,到2017年出现的AdamW成为最主流的选择,优化器的发展经历了70多年的时间。本系列从时间的角度出发,对神经网络的优化器进行梳理,希望能够帮助大家更好地理解优化器的发展历程。
欢迎关注我的GitHub和微信公众号,来不及解释了,快上船!
仓库上有原始的Markdown文件,完全开源,欢迎大家Star和Fork!