![]()
![]()
![]()
![]()
Learning LLM is all you need.
👉 点击 LearnLLM.AI | 学习大模型,从这里开始
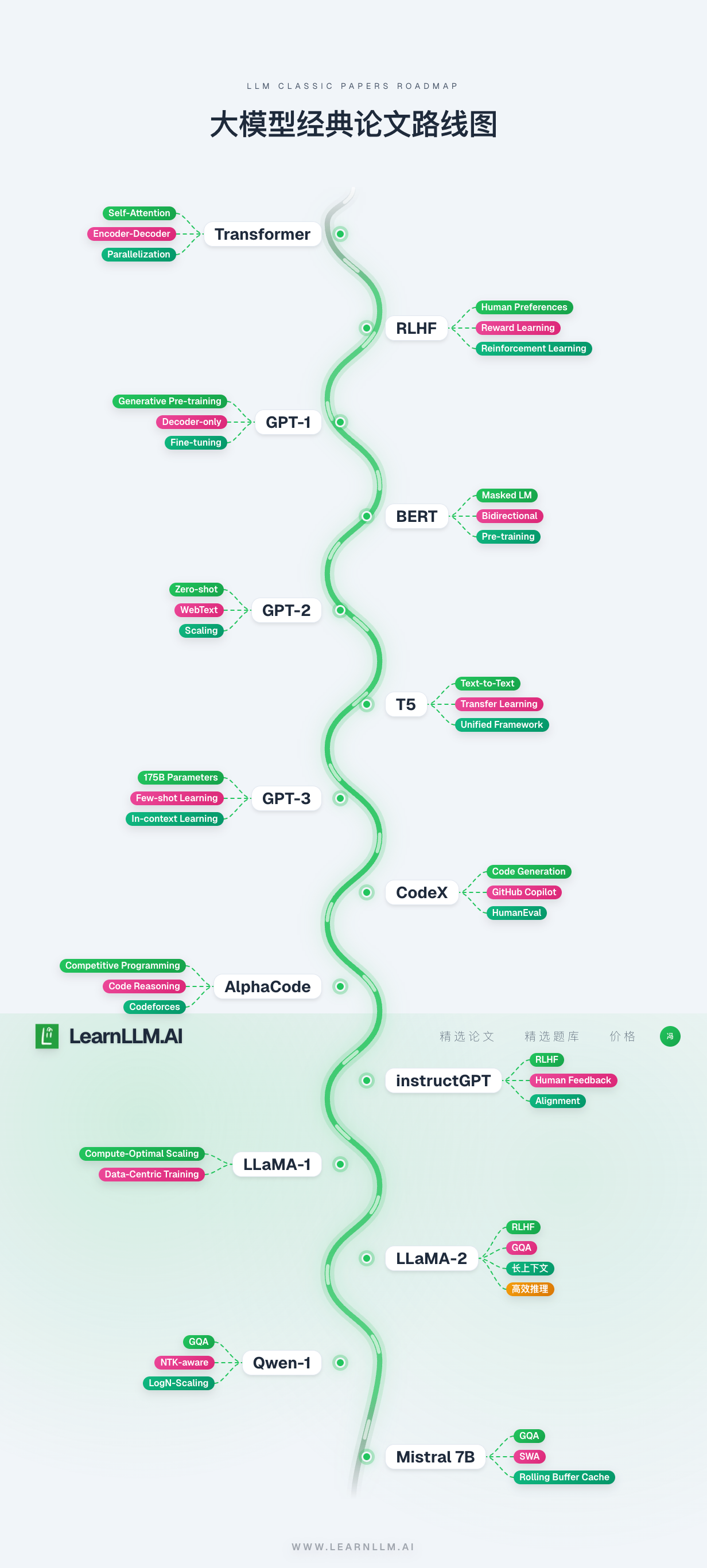
## LearnLLM.AI 核心亮点 **精选大模型面试题库**:覆盖从基础到前沿的实战题目,助您高效备战求职,抓住职业机遇; **系统化论文研读**:从2017年Transformer奠基性论文出发,按清晰的知识体系梳理技术演进,适合不同基础的开发者循序渐进地深度提升。 **专属优惠码** 我们为Github用户准备了限时专属优惠码:***GITHUB50*** ,期待在 [LearnLLM.AI](https://learnllm.ai?ref=github) 与您继续同行,共同成长! **配套视频教程(持续更新中)**: 👉 点击这里 [bilibili](https://space.bilibili.com/37863979/lists?sid=7144646) 👉 点击这里 [YouTube](https://www.youtube.com/@learnllm-ai) *如有疑问,欢迎随时联系我们。* *Happy Learning!* *LearnLLM.AI 团队* --- ## LLM 精选论文 | 时间 | 论文 | 介绍 | 视频 | 开始学习 | | --- | --- | --- | --- | --- | | 2017-06-12 | [Transformer](https://arxiv.org/abs/1706.03762) | 提出自注意力与 Transformer 架构 | [ ](https://www.bilibili.com/video/BV1gW6QBFEG4) | [](https://www.learnllm.ai/learning?milestone=gpt1&ref=github) |
| 2018-10-11 | [BERT](https://arxiv.org/abs/1810.04805) | 双向编码器:MLM + NSP | [
](https://www.bilibili.com/video/BV1gW6QBFEG4) | [](https://www.learnllm.ai/learning?milestone=gpt1&ref=github) |
| 2018-10-11 | [BERT](https://arxiv.org/abs/1810.04805) | 双向编码器:MLM + NSP | [ ](https://www.bilibili.com/video/BV1n2kFBgEJ5) | [](https://www.learnllm.ai/learning?milestone=bert&ref=github) |
| 2019-02-14 | [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) | 大规模无监督文本生成 | [
](https://www.bilibili.com/video/BV1n2kFBgEJ5) | [](https://www.learnllm.ai/learning?milestone=bert&ref=github) |
| 2019-02-14 | [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) | 大规模无监督文本生成 | [ ](https://www.bilibili.com/video/BV1VwkWBtEfe) | [](https://www.learnllm.ai/learning?milestone=gpt2&ref=github) |
| 2019-10-23 | [T5](https://arxiv.org/abs/1910.10683) | 文本到文本统一框架 | [
](https://www.bilibili.com/video/BV1VwkWBtEfe) | [](https://www.learnllm.ai/learning?milestone=gpt2&ref=github) |
| 2019-10-23 | [T5](https://arxiv.org/abs/1910.10683) | 文本到文本统一框架 | [ ](https://www.bilibili.com/video/BV1fHBfBdEGY) | [](https://www.learnllm.ai/learning?milestone=t5&ref=github) |
| 2020-05-28 | [GPT-3](https://arxiv.org/abs/2005.14165) | 大模型与少样本学习能力 | [
](https://www.bilibili.com/video/BV1fHBfBdEGY) | [](https://www.learnllm.ai/learning?milestone=t5&ref=github) |
| 2020-05-28 | [GPT-3](https://arxiv.org/abs/2005.14165) | 大模型与少样本学习能力 | [ ](https://www.bilibili.com/video/BV14Z63ByEWV) | [](https://www.learnllm.ai/learning?milestone=gpt3&ref=github) |
| 2020-10 | [ViT](https://arxiv.org/abs/2010.11929) | 将 Transformer 主干引入视觉领域 | [
](https://www.bilibili.com/video/BV14Z63ByEWV) | [](https://www.learnllm.ai/learning?milestone=gpt3&ref=github) |
| 2020-10 | [ViT](https://arxiv.org/abs/2010.11929) | 将 Transformer 主干引入视觉领域 | [ ](https://www.bilibili.com/video/BV1UYAuzaEHd/) | [](https://www.learnllm.ai/learning?milestone=vit&ref=github) |
| 2021-02 | [ViLT](https://arxiv.org/abs/2102.03334) | 极简视觉语言预训练架构 | [
](https://www.bilibili.com/video/BV1UYAuzaEHd/) | [](https://www.learnllm.ai/learning?milestone=vit&ref=github) |
| 2021-02 | [ViLT](https://arxiv.org/abs/2102.03334) | 极简视觉语言预训练架构 | [ ](https://www.bilibili.com/video/BV1vgXDBAEzM) | [](https://www.learnllm.ai/learning?milestone=vilt&ref=github) |
| 2021-02 | [CLIP](https://arxiv.org/abs/2103.00020) | 用自然语言监督实现零样本视觉学习 | [
](https://www.bilibili.com/video/BV1vgXDBAEzM) | [](https://www.learnllm.ai/learning?milestone=vilt&ref=github) |
| 2021-02 | [CLIP](https://arxiv.org/abs/2103.00020) | 用自然语言监督实现零样本视觉学习 | [ ](https://www.bilibili.com/video/BV1wGDvBfEv6) | [](https://www.learnllm.ai/learning?milestone=clip&ref=github) |
| 2021-02 | [DALL·E 1](https://arxiv.org/abs/2102.12092) | 自回归文本生成图像的开端 | [
](https://www.bilibili.com/video/BV1wGDvBfEv6) | [](https://www.learnllm.ai/learning?milestone=clip&ref=github) |
| 2021-02 | [DALL·E 1](https://arxiv.org/abs/2102.12092) | 自回归文本生成图像的开端 | [ ](https://www.bilibili.com/video/BV1zPXDBTE3c) | [](https://www.learnllm.ai/learning?milestone=dalle-1&ref=github) |
| 2021-07-07 | [CodeX](https://arxiv.org/abs/2107.03374) | 面向代码生成的 GPT 系列模型 | [
](https://www.bilibili.com/video/BV1zPXDBTE3c) | [](https://www.learnllm.ai/learning?milestone=dalle-1&ref=github) |
| 2021-07-07 | [CodeX](https://arxiv.org/abs/2107.03374) | 面向代码生成的 GPT 系列模型 | [ ](https://www.bilibili.com/video/BV1JC67BEE7b) | [](https://www.learnllm.ai/learning?milestone=codex&ref=github) |
| 2021-12 | [Stable Diffusion](https://arxiv.org/abs/2112.10752) | 潜空间扩散模型推动文生图开源化 | [
](https://www.bilibili.com/video/BV1JC67BEE7b) | [](https://www.learnllm.ai/learning?milestone=codex&ref=github) |
| 2021-12 | [Stable Diffusion](https://arxiv.org/abs/2112.10752) | 潜空间扩散模型推动文生图开源化 | [ ](https://www.bilibili.com/video/BV1HGDvBfE6g) | [](https://www.learnllm.ai/learning?milestone=stable-diffusion&ref=github) |
| 2022-02-08 | [AlphaCode](https://arxiv.org/abs/2203.07814) | 竞赛级代码生成系统 | [
](https://www.bilibili.com/video/BV1HGDvBfE6g) | [](https://www.learnllm.ai/learning?milestone=stable-diffusion&ref=github) |
| 2022-02-08 | [AlphaCode](https://arxiv.org/abs/2203.07814) | 竞赛级代码生成系统 | [ ](https://www.bilibili.com/video/BV1KbFTz2E8p) | [](https://www.learnllm.ai/learning?milestone=alphacode&ref=github) |
| 2022-03-04 | [InstructGPT](https://arxiv.org/abs/2203.02155) | 人类反馈对齐与指令微调 | [
](https://www.bilibili.com/video/BV1KbFTz2E8p) | [](https://www.learnllm.ai/learning?milestone=alphacode&ref=github) |
| 2022-03-04 | [InstructGPT](https://arxiv.org/abs/2203.02155) | 人类反馈对齐与指令微调 | [ ](https://www.bilibili.com/video/BV1qVFFzCERD) | [](https://www.learnllm.ai/learning?milestone=instructgpt&ref=github) |
| 2022-04 | [DALL·E 2](https://arxiv.org/abs/2204.06125) | 基于 CLIP Latents 的高保真文生图 | [
](https://www.bilibili.com/video/BV1qVFFzCERD) | [](https://www.learnllm.ai/learning?milestone=instructgpt&ref=github) |
| 2022-04 | [DALL·E 2](https://arxiv.org/abs/2204.06125) | 基于 CLIP Latents 的高保真文生图 | [ ](https://www.bilibili.com/video/BV1wCDQBkEbx) | [](https://www.learnllm.ai/learning?milestone=dalle-2&ref=github) |
| 2022-12 | [Whisper](https://arxiv.org/abs/2212.04356) | 大规模弱监督语音识别基础模型 | [
](https://www.bilibili.com/video/BV1wCDQBkEbx) | [](https://www.learnllm.ai/learning?milestone=dalle-2&ref=github) |
| 2022-12 | [Whisper](https://arxiv.org/abs/2212.04356) | 大规模弱监督语音识别基础模型 | [ ](https://www.bilibili.com/video/BV1FmRyBhE21) | [](https://www.learnllm.ai/learning?milestone=whisper&ref=github) |
| 2023-02-27 | [LLaMA-1](https://arxiv.org/pdf/2302.13971) | 高效开源预训练基座模型 | [
](https://www.bilibili.com/video/BV1FmRyBhE21) | [](https://www.learnllm.ai/learning?milestone=whisper&ref=github) |
| 2023-02-27 | [LLaMA-1](https://arxiv.org/pdf/2302.13971) | 高效开源预训练基座模型 | [ ](https://www.bilibili.com/video/BV1PqNMzZEw2) | [](https://www.learnllm.ai/learning?milestone=llama1&ref=github) |
| 2023-04 | [LLaVA](https://arxiv.org/abs/2304.08485) | 开源多模态指令微调的重要起点 | [
](https://www.bilibili.com/video/BV1PqNMzZEw2) | [](https://www.learnllm.ai/learning?milestone=llama1&ref=github) |
| 2023-04 | [LLaVA](https://arxiv.org/abs/2304.08485) | 开源多模态指令微调的重要起点 | [ ](https://www.bilibili.com/video/BV1c2DQB6EtH) | [](https://www.learnllm.ai/learning?milestone=llava&ref=github) |
| 2023-07-18 | [LLaMA-2](https://arxiv.org/abs/2307.09288) | LLaMA 升级版,开放商用 | [
](https://www.bilibili.com/video/BV1c2DQB6EtH) | [](https://www.learnllm.ai/learning?milestone=llava&ref=github) |
| 2023-07-18 | [LLaMA-2](https://arxiv.org/abs/2307.09288) | LLaMA 升级版,开放商用 | [ ](https://www.bilibili.com/video/BV1ckNMzsEXJ) | [](https://www.learnllm.ai/learning?milestone=llama2&ref=github) |
| 2023-08 | [Qwen-VL](https://arxiv.org/abs/2308.12966) | 通义千问早期视觉语言基座模型 | [
](https://www.bilibili.com/video/BV1ckNMzsEXJ) | [](https://www.learnllm.ai/learning?milestone=llama2&ref=github) |
| 2023-08 | [Qwen-VL](https://arxiv.org/abs/2308.12966) | 通义千问早期视觉语言基座模型 | [ ](https://www.bilibili.com/video/BV1i2dZBaE9T) | [](https://www.learnllm.ai/learning?milestone=qwen-vl&ref=github) |
| 2023-09-28 | [Qwen 1](https://arxiv.org/abs/2309.16609) | 通义千问第一代基座模型 | [
](https://www.bilibili.com/video/BV1i2dZBaE9T) | [](https://www.learnllm.ai/learning?milestone=qwen-vl&ref=github) |
| 2023-09-28 | [Qwen 1](https://arxiv.org/abs/2309.16609) | 通义千问第一代基座模型 | [ ](https://www.bilibili.com/video/BV1FdwtziE2M) | [](https://www.learnllm.ai/learning?milestone=qwen-1&ref=github) |
| 2023-10-10 | [Mistral 7B](https://arxiv.org/abs/2310.06825) | 高效 7B 级开源模型 | [
](https://www.bilibili.com/video/BV1FdwtziE2M) | [](https://www.learnllm.ai/learning?milestone=qwen-1&ref=github) |
| 2023-10-10 | [Mistral 7B](https://arxiv.org/abs/2310.06825) | 高效 7B 级开源模型 | [ ](https://www.bilibili.com/video/BV19uwbzdEjj) | [](https://www.learnllm.ai/learning?milestone=mistral-7b&ref=github) |
| 2023-12 | [LVM](https://arxiv.org/abs/2312.00785) | 纯视觉自回归建模的大视觉模型路线 | [
](https://www.bilibili.com/video/BV19uwbzdEjj) | [](https://www.learnllm.ai/learning?milestone=mistral-7b&ref=github) |
| 2023-12 | [LVM](https://arxiv.org/abs/2312.00785) | 纯视觉自回归建模的大视觉模型路线 | [ ](https://www.bilibili.com/video/BV1rzdZBTENn) | [](https://www.learnllm.ai/learning?milestone=lvm&ref=github) |
| 2024-02 | [Mixtral 8x7B](https://arxiv.org/abs/2401.04088) | 开源稀疏 MoE 的代表作 | [
](https://www.bilibili.com/video/BV1rzdZBTENn) | [](https://www.learnllm.ai/learning?milestone=lvm&ref=github) |
| 2024-02 | [Mixtral 8x7B](https://arxiv.org/abs/2401.04088) | 开源稀疏 MoE 的代表作 | [ ](https://www.bilibili.com/video/BV116AuzoEMk) | [](https://www.learnllm.ai/learning?milestone=mixtral-8x7b&ref=github) |
| 2024-03 | [Gemma 1](https://arxiv.org/abs/2403.08295) | Google 轻量开源模型家族首作 | [
](https://www.bilibili.com/video/BV116AuzoEMk) | [](https://www.learnllm.ai/learning?milestone=mixtral-8x7b&ref=github) |
| 2024-03 | [Gemma 1](https://arxiv.org/abs/2403.08295) | Google 轻量开源模型家族首作 | [ ](https://www.bilibili.com/video/BV12jR1B6EKB) | [](https://www.learnllm.ai/learning?milestone=gemma1&ref=github) |
| 2024-05 | [DeepSeek-V2](https://arxiv.org/abs/2405.04434) | 高效 MoE 语言模型,兼顾性能与推理经济性 | [
](https://www.bilibili.com/video/BV12jR1B6EKB) | [](https://www.learnllm.ai/learning?milestone=gemma1&ref=github) |
| 2024-05 | [DeepSeek-V2](https://arxiv.org/abs/2405.04434) | 高效 MoE 语言模型,兼顾性能与推理经济性 | [ ](https://www.bilibili.com/video/BV1gGZFBtEnB) | [](https://www.learnllm.ai/learning?milestone=deepseek-v2&ref=github) |
| 2024-06 | [ChatGLM](https://arxiv.org/abs/2406.12793) | 从 GLM-130B 演进到 GLM-4 的国产模型家族 | [
](https://www.bilibili.com/video/BV1gGZFBtEnB) | [](https://www.learnllm.ai/learning?milestone=deepseek-v2&ref=github) |
| 2024-06 | [ChatGLM](https://arxiv.org/abs/2406.12793) | 从 GLM-130B 演进到 GLM-4 的国产模型家族 | [ ](https://www.bilibili.com/video/BV1yh5t6dEvG) | [](https://www.learnllm.ai/learning?milestone=chatglm&ref=github) |
| 2024-07 | [Llama 3](https://arxiv.org/abs/2407.21783) | Meta 新一代开源旗舰模型 | [
](https://www.bilibili.com/video/BV1yh5t6dEvG) | [](https://www.learnllm.ai/learning?milestone=chatglm&ref=github) |
| 2024-07 | [Llama 3](https://arxiv.org/abs/2407.21783) | Meta 新一代开源旗舰模型 | [ ](https://www.bilibili.com/video/BV1x85t64Exx) | [](https://www.learnllm.ai/learning?milestone=llama3-1&ref=github) |
| 2024-07 | [Gemma 2](https://arxiv.org/abs/2408.00118) | 在实用尺寸上继续提升开源模型性能 | | [](https://www.learnllm.ai/learning?milestone=gemma2&ref=github) |
| 2025-03 | [Gemma 3](https://arxiv.org/abs/2503.19786) | 原生多模态与 128K 长上下文的 Gemma | | [](https://www.learnllm.ai/learning?milestone=gemma3&ref=github) |
持续更新中...
](https://www.bilibili.com/video/BV1x85t64Exx) | [](https://www.learnllm.ai/learning?milestone=llama3-1&ref=github) |
| 2024-07 | [Gemma 2](https://arxiv.org/abs/2408.00118) | 在实用尺寸上继续提升开源模型性能 | | [](https://www.learnllm.ai/learning?milestone=gemma2&ref=github) |
| 2025-03 | [Gemma 3](https://arxiv.org/abs/2503.19786) | 原生多模态与 128K 长上下文的 Gemma | | [](https://www.learnllm.ai/learning?milestone=gemma3&ref=github) |
持续更新中...