LLMForEverybody
CRUD/ETL工程师的末日?从NL2SQL到ChatBI
1. 导入
前几日和朋友聚餐时,我们聊到了他目前的新工作,主要是编写 SQL。于是,我们进一步探讨了 AIGC(人工智能生成内容)是否能够解放他的生产力。
2024Q2陆续有互联网大厂chatbi落地的消息传出:比如阿里云+一汽落地了chatbi报表体系;火山引擎在飞书发布了datawind chatbi工具,支持在制定数据集上的chatbi能力。 在ChatBI落地中,会遇到哪些问题,该如何解决呢?
2. 术语
我们快速过下几个名词术语,懂的小伙伴可以跳过这节。
CRUD
增加(Create,意为“创建”)、删除(Delete)、查询(Read,意为“读取”)、改正(Update,意为“更新”),在计算机程序语言中是一连串常见的动作行为,而其行为通常是为了针对某个特定资源所作出的举动(例如:创建资料、读取资料等)

ETL
ETL(Extract, Transform, Load)是一种数据集成技术,用于将分散在不同数据源中的数据经过提取、清洗、转换和整合,最终加载到一个统一的数据存储系统中,如数据仓库或数据湖,以便于进一步的分析和决策支持。
NL2SQL
NL2SQL(Natural Language to SQL)技术是一种将自然语言查询转换为SQL查询语句的方法,它的目标是让用户能够用自然语言与数据库进行交互,从而提高查询数据的效率。
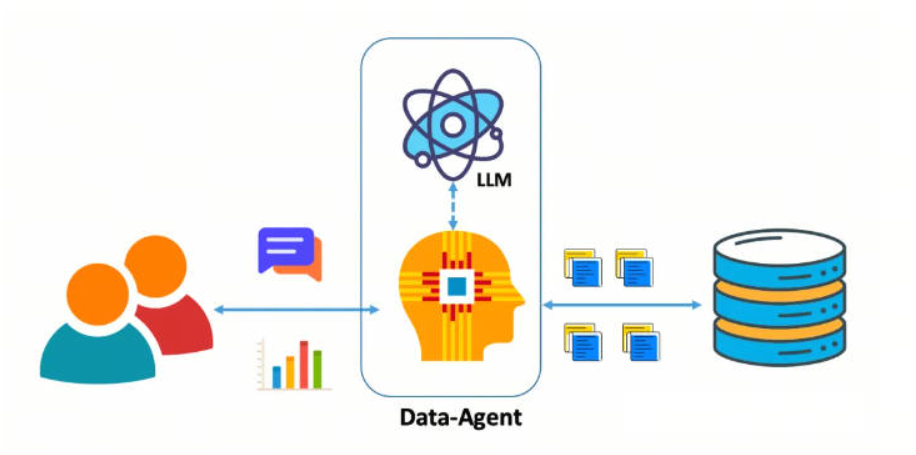
ChatBI
ChatBI(Chat Business Intelligence)是一种新兴的商业智能工具,它通过自然语言处理(NLP)技术使用户能够以对话的形式与数据分析系统进行交互,从而快速获取数据洞察和分析结果。这种工具的优势在于提高了数据分析的效率,降低了使用门槛,使得非技术背景的用户也能够轻松地进行数据探索和获取分析结论。 与传统BI工具相比,ChatBI提供了更为自然和直观的交互方式,用户无需学习复杂的数据操作技能,就像与朋友聊天一样简单。
3. 难点之一: 数据结构复杂
企业信息系统的数据结构复杂性远远超过几个简单的 Excel 文件,一个大型企业应用可能存在几百上千个数据实体。 当前大模型的能力不足以处理如此多的数据实体,因此ChatBI的实际落地有两个流派:
大模型派
这派以大模型厂商为主,这些头部玩家会收集大量的数据,试图通过提高大模型的能力,来应对企业级的复杂度。

大宽表派
这派以中小BI厂商为主,这些原有的BI厂商使用的会是商业/开源的大模型,一般没有资源提高模型能力,于是会花费人力定制化的把企业级的多表做出大宽表。这在生产落地中往往很实用。

4. 难点之二:大模型的幻觉
大模型出现幻觉,简而言之就是“胡说八道”。 用《A Survey on Hallucination in Large Language Models》1文中的话来讲,是指模型生成的内容与现实世界事实或用户输入不一致的现象。 研究人员将大模型的幻觉分为事实性幻觉(Factuality Hallucination)和忠实性幻觉(Faithfulness Hallucination)。
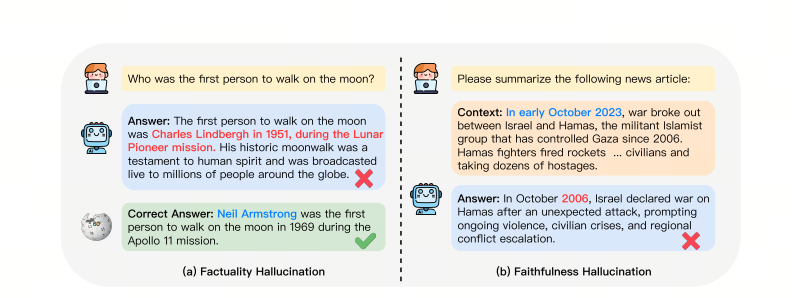
事实性幻觉
是指模型生成的内容与可验证的现实世界事实不一致。
比如问模型“第一个在月球上行走的人是谁?”,模型回复“Charles Lindbergh在1951年月球先驱任务中第一个登上月球”。实际上,第一个登上月球的人是Neil Armstrong。
事实性幻觉又可以分为事实不一致(与现实世界信息相矛盾)和事实捏造(压根没有,无法根据现实信息验证)。
忠实性幻觉
则是指模型生成的内容与用户的指令或上下文不一致。
比如让模型总结今年10月的新闻,结果模型却在说2006年10月的事。
忠实性幻觉也可以细分,分为指令不一致(输出偏离用户指令)、上下文不一致(输出与上下文信息不符)、逻辑不一致三类(推理步骤以及与最终答案之间的不一致)。
5. 处理幻觉
在生产中,我们不喜欢hallucinations,我们需要准确的、正确的回答。
在实际生产落地中,我们会循序渐进的采用如下策略来提高准确性,降低幻觉:
| 策略 | 难度 | 数据要求 | 准确性提升 |
|---|---|---|---|
| Prompt engineering | 低 | 无 | 26% |
| Self-reflection | 低 | 无 | 26-40% |
| Few-shot learning (with RAG) | 中 | 少量 | 50% |
| Instruction Fine-tuning | 高 | 中等 | 40-60% |
6. Prompt Engineering
Prompt Engineering 是优化 prompts 以获得有效输出的艺术和科学。它涉及设计、编写和修改 prompts,以引导 AI 模型生成高质量、相关且有用的响应。

7. Self-reflection
自我反思在大模型中经常被用于减少幻觉现象,即模型生成听起来合理但实际上不准确或无意义的信息。通过交互式自我反思方法,可以利用LLMs的多任务能力,生成、评分并不断改进知识,直到达到满意的事实性水平。
如何在工作流里面嵌入self-reflection?以一个NL2SQL2的例子来说明:
第一次交互
question = ''
prompt = f'{question}'
plain_query = llm.invoke(prompt)
try:
df = pd.read_sql(plain_query)
print(df)
except Exception as e:
print(e)
reflection
reflection = f"Question: {question}. Query: {plain_query}. Error:{e}, so it cannot answer the question. Write a corrected sqlite query."
第二次交互
reflection_prompt = f'{reflection}'
reflection_query = llm.invoke(reflection_prompt)
try:
df = pd.read_sql(reflection_query )
print(df)
except Exception as e:
print(e)
你可以通过反思,我们可以不断改进我们的问题,直到我们得到我们想要的答案。
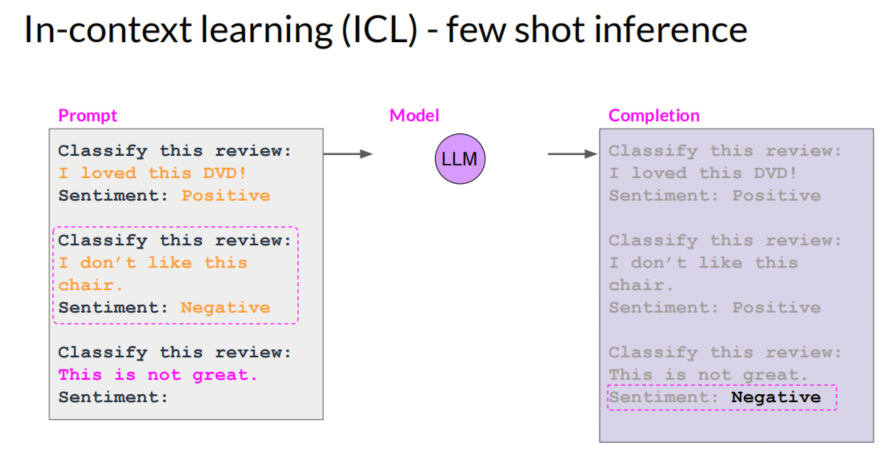
8. Few-shot learning (with RAG)
Few-shot learning
在prompt里面给出少量例子,帮助大模型更好的理解任务。
RAG
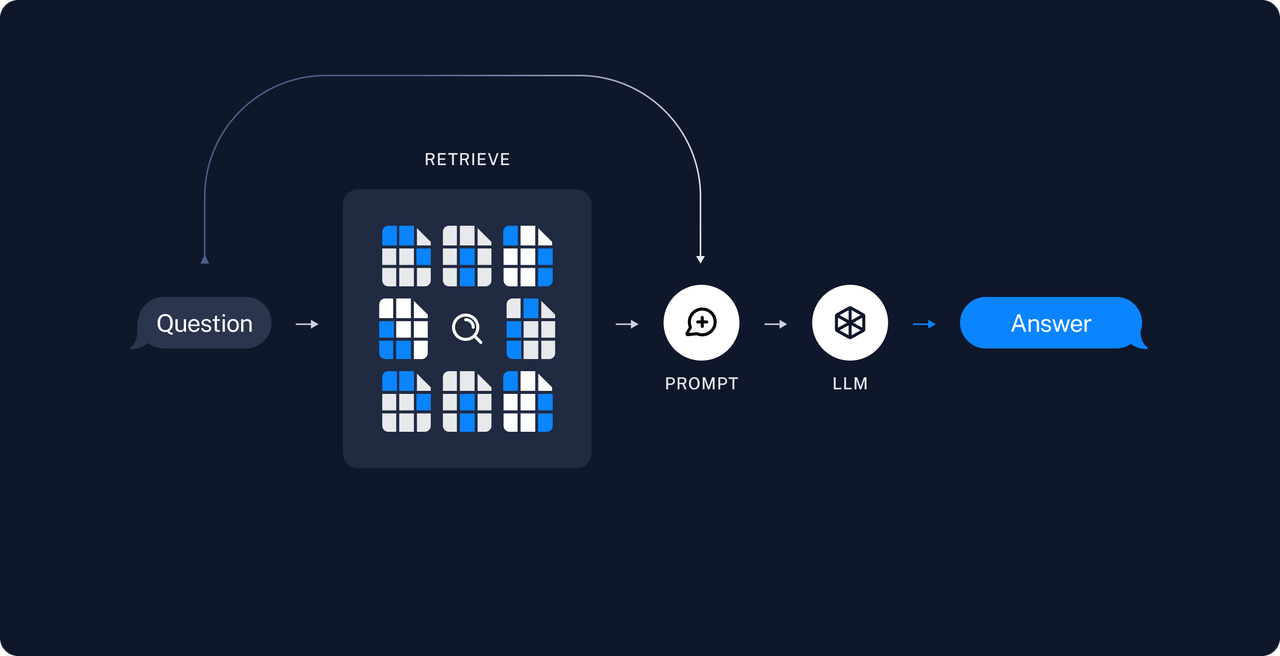
检索增强生成(Retrieval-Augmented Generation,简称 RAG)通过结合大型语言模型(LLM)和信息检索系统来提高生成文本的准确性和相关性。这种方法允许模型在生成回答之前,先从权威知识库中检索相关信息,从而确保输出内容的时效性和专业性,无需对模型本身进行重新训练。
RAG技术之所以重要,是因为它解决了LLM面临的一些关键挑战,例如虚假信息的提供、过时信息的生成、非权威来源的依赖以及由于术语混淆导致的不准确响应。通过引入RAG,可以从权威且预先确定的知识来源中检索信息,增强了对生成文本的控制,同时提高了用户对AI解决方案的信任度。
Few-shot with RAG
在基于RAG的方法中,我们可以根据查询(query)与候选例子之间的相似度,动态地选取最相关的案例作为 few-shot 学习的示例。这种方法不仅提高了模型生成的准确性,还使得模型在处理不同类型的查询时更加灵活和智能。
具体来说,RAG 通过评估查询与候选例子之间的相似度,从候选例子库中召回最相关的案例。这些被选中的案例将作为 few-shot 学习的示例,帮助模型更好地理解和生成与查询相关的内容。通过这种动态选择的方式,模型能够根据每个查询的具体需求,灵活调整所使用的示例,从而实现更高效的学习和生成。
这种方法的优势在于,它能够充分利用现有的知识库,动态响应不同的查询需求,极大地提升了模型的实用性和准确性。
Few-shot examples:
examples = [
{"input": "List all artists.", "query": "SELECT * FROM Artist;"},
{
"input": "Find all albums for the artist 'AC/DC'.",
"query": "SELECT * FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'AC/DC');",
},
{
"input": "List all tracks in the 'Rock' genre.",
"query": "SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');",
},
{
"input": "Find the total duration of all tracks.",
"query": "SELECT SUM(Milliseconds) FROM Track;",
},
{
"input": "List all customers from Canada.",
"query": "SELECT * FROM Customer WHERE Country = 'Canada';",
},
{
"input": "How many tracks are there in the album with ID 5?",
"query": "SELECT COUNT(*) FROM Track WHERE AlbumId = 5;",
},
{
"input": "Find the total number of invoices.",
"query": "SELECT COUNT(*) FROM Invoice;",
},
{
"input": "List all tracks that are longer than 5 minutes.",
"query": "SELECT * FROM Track WHERE Milliseconds > 300000;",
},
{
"input": "Who are the top 5 customers by total purchase?",
"query": "SELECT CustomerId, SUM(Total) AS TotalPurchase FROM Invoice GROUP BY CustomerId ORDER BY TotalPurchase DESC LIMIT 5;",
},
{
"input": "Which albums are from the year 2000?",
"query": "SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';",
},
{
"input": "How many employees are there",
"query": 'SELECT COUNT(*) FROM "Employee"',
},
]
动态选择最相关的案例:
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix='''You are a SQLite expert. Given an input question, create a syntactically correct SQLite query to run.
Unless otherwise specificed, do not return more than {top_k} rows.\n\n
Here is the relevant table info: {table_info}\n\nBelow are a number of examples of questions and their corresponding SQL queries.''',
suffix="User input: {input}\nSQL query: ",
input_variables=["input", "top_k", "table_info"],
)
Few-shot with RAG:
chain = create_sql_query_chain(llm, db, prompt)
chain.invoke({"question": "how many artists are there?"})
9. Instruction Fine-tuning
在生产上,微调是最困难的,因为2:
- 需要更多计算才能获得相同的准确度,有时候超过 10000 或 1百万倍;
- 无法在多个 GPU 上有效并行化,这样会丢失大量空闲GPU计算资源;
- 在实际用例上容易崩溃,无法在生产中连续微调和推理;
- LLM 没有改进,难以根据每一个用例、模式、数据集进行调整
- 不易使用,无法扩展(GPU 和内存问题)
- 将微调与推理相结合很容易出错
同时,你需要考虑的是如何获取高质量的数据?
下面以一个简单的cheet-sheet来说明获取数据的步骤2:
- 你拥有的数据比你想象的要多
- 首先,盘点一下你拥有的数据。
- 你通常拥有大量数据 - 只是格式不符合 LLMS 的要求。
- 你不想手动标记数据或清理数据以重新格式化。
- 但没关系,LLM 可以帮你!只要你指定正确的格式。
总结
通过上述四个策略,我们可以有效地提高ChatBI的准确性,降低幻觉的发生。在实际生产中,我们可以根据具体情况选择合适的策略,或者结合多种策略,以获得更好的效果。