LLMForEverybody
LoRA不是唯一选择,Adapters微调大模型的奥秘(三)QLoRA
1.技术解读
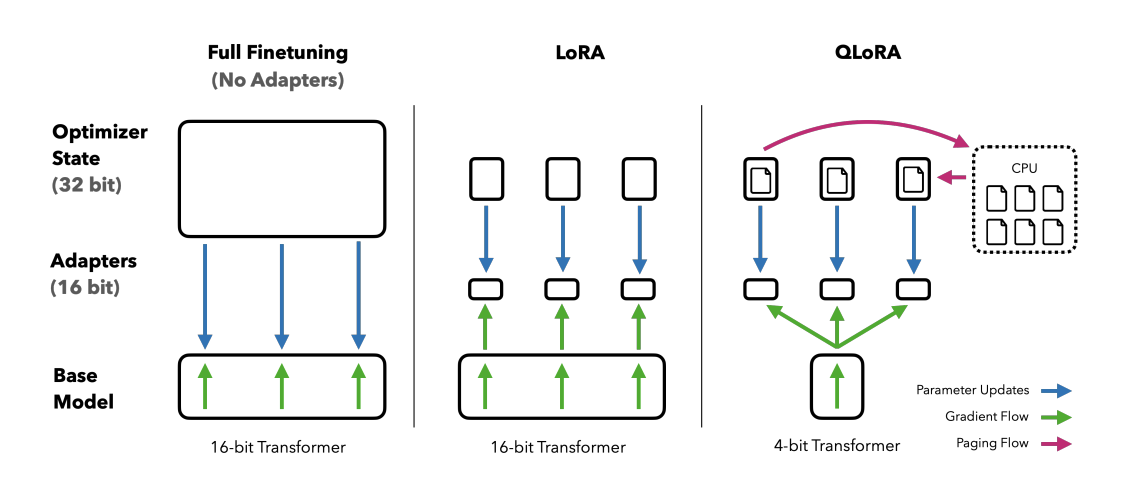
QLoRA(Quantized Low-Rank Adaptation)是一种针对大型预训练语言模型(LLM)的高效微调技术。它结合了量化和低秩适配(LoRA)两种技术,旨在减少模型微调过程中的内存占用和计算成本,同时尽量保持模型性能。
在QLoRA中,首先对模型的权重进行4位量化,这意味着模型的每个权重被表示为4位的数值,显著减少了模型的内存占用。量化后的模型参数以一种称为NormalFloat(NF4)的数据类型存储,这种数据类型特别适合表示正态分布的数据,并且可以比传统的4位整数或浮点数提供更好的量化效果。
接下来,QLoRA利用LoRA技术,通过在模型中引入可训练的低秩矩阵来进一步微调模型。这些低秩矩阵作为适配器,被添加到模型的特定层中,并且只有这些适配器的参数在微调过程中被更新,而模型的原始参数保持不变。这样做的好处是,可以针对特定任务微调模型的行为,而不需要对整个模型进行昂贵的更新。
此外,QLoRA还采用了一种称为双重量化的技术,对量化过程中使用的缩放因子(scale factor)和偏移量(offset)进行再次量化,从而进一步减少内存占用。
QLoRA的另一个关键技术是利用NVIDIA的统一内存进行分页优化。这种方法可以有效地管理内存使用,特别是在处理长序列数据时,可以避免内存峰值过高的问题。
2.直观理解
想象一下,你有一本厚厚的百科全书,这本书包含了所有的知识(就像一个大型预训练语言模型)。现在,你想根据你的特定需求来更新这本书(微调模型)。但是,整本书重新打印非常耗时且成本高昂。
QLoRA的做法就像是你不需要重新打印整本书,你只需要在书的某些页面上贴几个小便利贴(低秩适配器)。这些便利贴包含了你需要的新信息,而且它们很小,不会占用太多空间。
-
量化:首先,你把百科全书中的一些文字和图片变成更小的版本,比如把彩色照片换成黑白的,并且缩小尺寸(这就像是4位量化,减少模型大小)。
-
便利贴:然后,你在需要更新的页面上贴上便利贴,这些便利贴包含了最新的信息(这就像是在模型的关键部分添加低秩适配器)。
-
节省空间:由于便利贴很小,你不需要为整本书找到额外的空间(这就像是QLoRA减少了模型微调时的内存需求)。
-
保持性能:尽管你只更新了一小部分内容,但这本书仍然非常有用,因为大部分知识都还在(这就像是QLoRA在减少资源消耗的同时,保持了模型的性能)。
-
更高效:你不需要重新学习整本书,只需要看看那些便利贴,就可以快速找到你需要的信息(这就像是QLoRA使得模型微调更加高效)。
所以,QLoRA就是一种聪明的方法,让你在不重新打印整本百科全书的情况下,快速且经济地更新知识。
参考
[1] QLORA: Efficient Finetuning of Quantized LLMs
欢迎关注我的GitHub和微信公众号[真-忒修斯之船],来不及解释了,快上船!
仓库上有原始的Markdown文件,完全开源,欢迎大家Star和Fork!