LLMForEverybody
大模型训练框架(一)综述
1. 导入
尽管 PyTorch 是一个非常流行的深度学习框架,它在动态计算图、易用性、灵活性和强大的社区支持方面具有许多优点 ,但在大模型训练方面,我们需要更专业的框架来满足特定的需求,最主要的原因是:分布式训练支持.
分布式训练支持:大型模型通常需要在多个 GPU 或 TPU 上进行分布式训练。虽然 PyTorch 支持分布式训练,但大模型训练框架可能提供了更优化的分布式训练策略,如模型并行性和数据并行性。
在之前的分享中,我提到了分布式训练的并行技术,参见文章:
大模型分布式训练并行技术(一)综述
大模型分布式训练并行技术(二)数据并行
大模型分布式训练并行技术(三)流水线并行
大模型分布式训练并行技术(四)张量并行
大模型分布式训练并行技术(五)混合并行
2. 并行技术简单介绍
在大模型训练中,我们通常会使用以下几种并行技术:
- 数据并行 DataParallel (DP) - 相同的设置被复制多次,每次都输入一部分数据。处理是并行进行的,所有设置在每个训练步骤结束时同步。
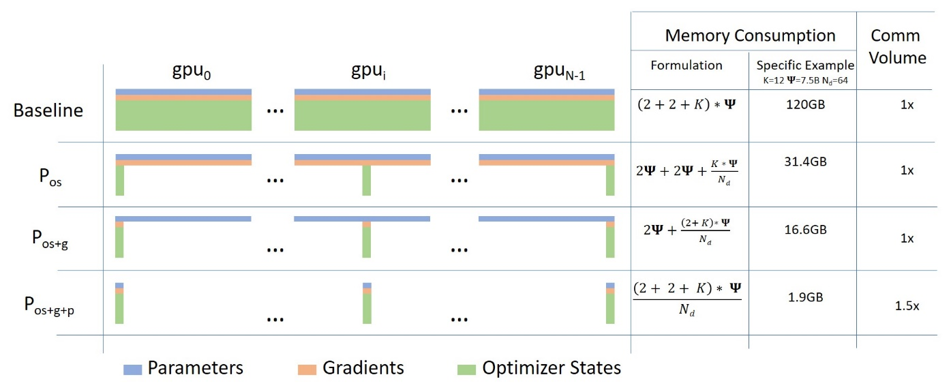
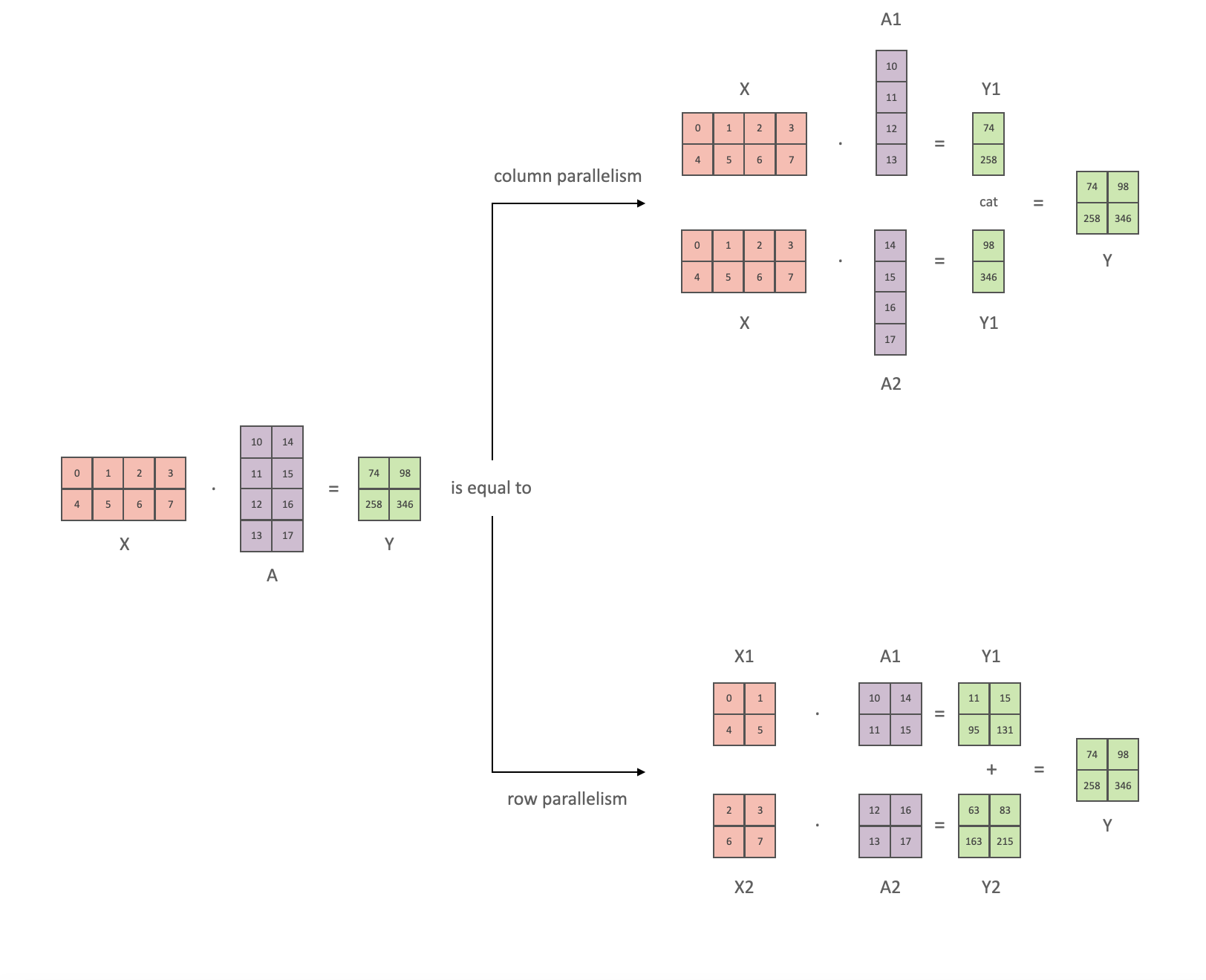
- 张量并行 TensorParallel (TP) - 每个张量被分成多个块,因此不是将整个张量驻留在单个 gpu 上,而是将张量的每个分片驻留在其指定的 gpu 上。在处理过程中,每个分片在不同的 GPU 上单独并行处理,结果在步骤结束时同步。这就是所谓的水平并行,因为拆分发生在水平层面。
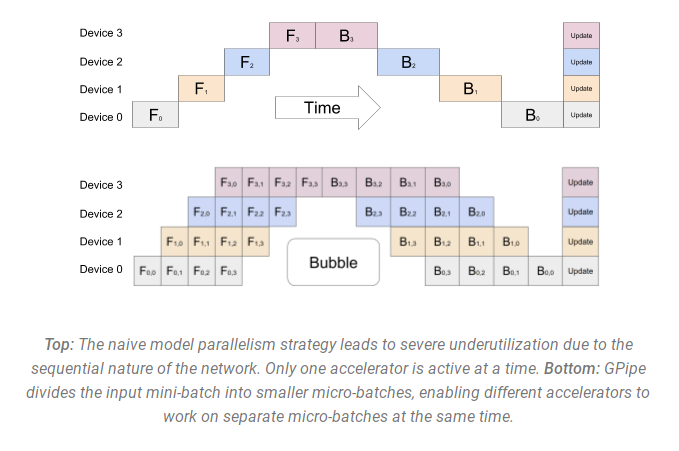
- 管道并行(流水线并行) PipelineParallel (PP) - 模型在多个 GPU 上垂直(层级)拆分,因此只有一层或几层模型放在单个 gpu 上。每个 gpu 并行处理管道的不同阶段并处理一小部分批次。
- 混合并行 MixedParallel (MP) - 混合并行是将数据并行、模型并行和管道并行结合在一起的一种方法。这种方法可以在多个 gpu 上同时进行数据并行和模型并行,同时在每个 gpu 上进行管道并行。
3. 训练框架
当前,有许多大型模型训练框架可以帮助我们加速训练大型模型,这些框架通常提供了更优化的分布式训练策略,如模型并行性和数据并行性。我选取了最具影响力的四个主流框架,分别是:
- FSDP
Fully Sharded Data Parallel (FSDP)1 是一种数据并行方法,最早是在2021年由 FairScale-FSDP 提出的,并在后续被集成到了 PyTorch 1.11 版本中。
FSDP 可以看作是微软 Deepspeed 框架中提出的三种级别的 ZERO 算法中的 ZERO-3 的实现。它通过将模型的梯度、优化器状态和参数进行分片操作,使得每个 GPU 只存储部分参数信息,从而优化了资源的利用和提高了训练效率。此外,FSDP 也与包括 Tensor 实现、调度器系统和 CUDA 内存缓存分配器在内的几个关键 PyTorch 核心组件紧密协同设计,以提供非侵入式用户体验和高训练效率。
- DeepSpeed
DeepSpeed2是由微软研究团队开发的一个深度学习优化库,旨在提供高效、可扩展的大规模模型训练能力。它通过采用先进的并行化策略、内存优化技术(如 ZeRO 内存优化器)和混合精度训练来显著提高训练效率和减少资源需求。
- Megatron-LM
Megatron-LM3 是由 NVIDIA 推出的一个用于训练大型语言模型的分布式训练框架,它支持在多节点、多 GPU 环境下进行模型训练。Megatron-LM 通过模型并行(Model Parallelism)的方式,允许训练具有数千亿参数的模型。该框架综合应用了数据并行(Data Parallelism)、张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)来训练像 GPT-3 这样的大型模型。
一个小tips:transformer 也可以是变形金刚,而 megatron 是威震天。

- Accelerate
Hugging Face 的 Accelerate4是一个用于简化和加速深度学习模型训练的库,它支持在多种硬件配置上进行分布式训练,包括 CPU、GPU、TPU 等。Accelerate 允许用户轻松切换不同的并行策略,同时它还支持混合精度训练,可以进一步提升训练效率。
以下是各种框架对并行策略(截至2024/10/12)的支持情况:
| 框架 | DP | PP | TP | 3D并行 |
|---|---|---|---|---|
| Pytorch(FSDP) | 是 | 否 | 否 | 否 |
| DeepSpeed | 是 | 是 | 是 | 是 |
| Megatron-LM | 是 | 是 | 是 | 是 |
| Accelerate | 是 | 否 | 否 | 否 |
参考
[1] Getting Started with Fully Sharded Data Parallel(FSDP)
[2] DeepSpeed
[3] Megatron-LM
[4] Accelerate
[5] 我自己的知乎
欢迎关注我的GitHub和微信公众号[真-忒修斯之船],来不及解释了,快上船!
仓库上有原始的Markdown文件,完全开源,欢迎大家Star和Fork!