LLMForEverybody
大模型并行策略[中文翻译]
写在最前面
本文是对Hugging Face官方文档的翻译,原文链接在这里:https://huggingface.co/docs/transformers/v4.15.0/en/parallelism
由于译者水平有限,翻译过程中难免会有错误,还请大家多多包涵. 如果有任何问题,欢迎在评论区指出,我会尽快修改.
=======================正文开始==============
并行技术概述
在现代机器学习中,各种并行方法用于:
-
将非常大的模型加载到资源有限的硬件上 - 例如,t5-11b 仅模型参数就达到 45GB
-
显著加快训练速度 - 只需几个小时即可完成原本需要一年时间的训练
我们将首先深入讨论各种 1D 并行技术及其优缺点,然后研究如何将它们组合成 2D 和 3D 并行,以实现更快的训练并支持更大的模型。还将介绍各种其他强大的替代方法。
虽然主要概念很可能适用于任何其他框架,但本文重点介绍基于 PyTorch 的实现。
概念
以下是本文后面将深入介绍的主要概念的简要说明。
-
数据并行 DataParallel (DP) - 相同的设置被复制多次,每次都输入一部分数据。处理是并行进行的,所有设置在每个训练步骤结束时同步。
-
张量并行 TensorParallel (TP) - 每个张量被分成多个块,因此不是将整个张量驻留在单个 gpu 上,而是将张量的每个分片驻留在其指定的 gpu 上。在处理过程中,每个分片在不同的 GPU 上单独并行处理,结果在步骤结束时同步。这就是所谓的水平并行,因为拆分发生在水平层面。
-
管道并行 PipelineParallel (PP) - 模型在多个 GPU 上垂直(层级)拆分,因此只有一层或几层模型放在单个 gpu 上。每个 gpu 并行处理管道的不同阶段并处理一小部分批次。
-
零冗余优化器 Zero Redundancy Optimizer (ZeRO) - 也执行与 TP 类似的张量分片,不同之处在于整个张量会及时重建以进行前向或后向计算,因此无需修改模型。它还支持各种卸载技术,以弥补有限的 GPU 内存。
-
分片DDP(Sharded DDP) - 是 ZeRO 基础概念的另一个名称,ZeRO 的其他各种实现都使用它。
数据并行 (DP)
作为Pytorch 的内置功能,DataParallel (DP) 和 DistributedDataParallel (DDP)简单易用,大多数仅拥有 2 个 GPU 的用户通过其已经享受到了更快的训练速度。
ZeRO 数据并行 (ZeRO-DP)
下图描述了由 ZeRO 驱动的数据并行性 (ZeRO-DP),该图来源这篇博客
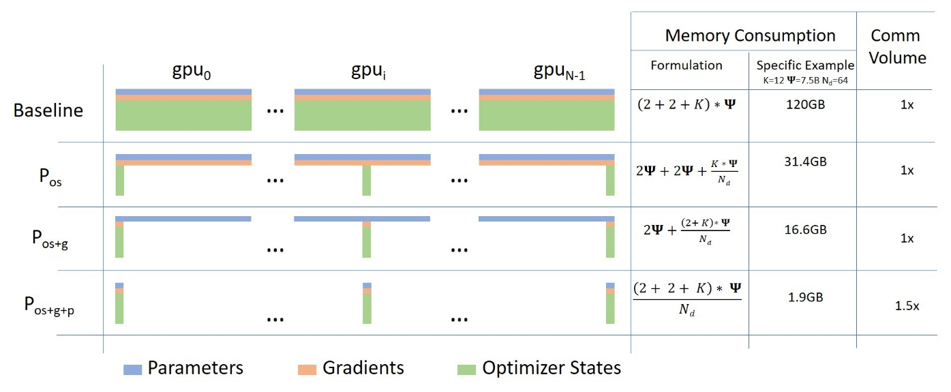
理解起来可能有点困难,但实际上这个概念相当简单。这只是通常的 DataParallel (DP),只不过每个 GPU 只存储其中的一部分,而不是复制完整的模型参数、梯度和优化器状态。然后在运行时,当给定层需要完整的层参数时,所有 GPU 都会同步以相互提供它们遗漏的部分 - 就是这样。
考虑这个具有 3 层的简单模型,其中每层有 3 个参数:
| La | Lb | Lc |
|---|---|---|
| a0 | b0 | c0 |
| a1 | b1 | c1 |
| a2 | b2 | c2 |
La 层具有权重 a0、a1 和 a2。
如果我们有 3 个 GPU,则分片 DDP(= Zero-DP)会将模型拆分到 3 个 GPU 上,如下所示:
GPU0: La | Lb | Lc —|—-|— a0 | b0 | c0
GPU1: La | Lb | Lc —|—-|— a1 | b1 | c1
GPU2: La | Lb | Lc —|—-|— a2 | b2 | c2
如果你想象一下典型的 DNN 图,在某种程度上,这和张量并行是一样的水平切片。垂直切片是将整个层组放在不同的 GPU 上。
但这只是一个起点。
现在,每个 GPU 都将获得在 DP 中工作的常规小批量:
```Plain Text x0 => GPU0 x1 => GPU1 x2 => GPU2
输入未经修改 - 它们(输入)认为它们将被正常模型处理。
首先,输入到达 La 层。
让我们只关注 GPU0:x0 需要 a0、a1、a2 参数来完成其前向路径,但 GPU0 只有 a0 - 它从GPU1 拿到 a1,从 GPU2 拿到 a2,将模型的所有部分组合在一起。
同时,GPU1 获得小批量(mini-batch) x1,它只有 a1,但需要 a0 和 a2 参数,因此它从 GPU0 和 GPU2 获取这些参数。
获得输入 x2 的 GPU2 也是如此。它从 GPU0 和 GPU1 获取 a0 和 a1,并使用其 a2 重建完整张量。
所有 3 个 GPU 都重建了完整张量,并进行前向传播。
一旦计算完成,不再需要的数据就会被丢弃 - 它仅在计算期间使用。重建是通过pre-fetch高效完成的。
整个过程先对 Lb 层重复,然后对 Lc 层向前重复,再对 Lc 层向后重复,然后向后 Lc -> Lb -> La。
对我来说,这听起来像是一种有效的团体背包旅行重量分配策略(老外真的很爱背包旅行啊):
```Plain Text
A扛帐篷
B扛炉子
C扛斧头
现在,他们每天晚上都会与他人分享自己拥有的东西,并从他人那里获得自己没有的东西,早上收拾好分配给他们的装备,继续上路。这就是Sharded DDP/ZeRO DP。
将这种策略与简单的策略进行比较,简单的策略是每个人都必须携带自己的帐篷、炉子和斧头,这会低效得多。这是(简单策略) Pytorch 中的 DataParallel(DP 和 DDP)。
在阅读有关此主题的文献时,你可能会遇到以下同义词:Sharded分片、Partitioned分区。
如果你密切关注 ZeRO 对模型权重进行分区的方式 - 它看起来非常类似于稍后将讨论的张量并行性。这是因为它对每个层的权重进行分区/分片,与下面讨论的垂直模型并行性不同。
实现:
DeepSpeed ZeRO-DP stages 1+2+3
Fairscale ZeRO-DP stages 1+2+3
简单模型并行(垂直)和管道并行(PP)
简单模型并行Model Parallel (MP) 是指将模型层组分布在多个 GPU 上。该机制相对简单 - 将所需的层 (使用函数).to() 切换到所需的设备,接着每当数据进出时,会切换到与层相同的设备,其余部分保持不变。
我们将其称为垂直MP(Vertical MP),因为如果你还记得大多数模型的绘制方式,我们会垂直切分层。例如,下图显示一个 8 层模型:

我们只是将其垂直切成两半,将 0-3 层放在 GPU0 上,将 4-7 层放在 GPU1 上。
现在,当数据从 0 层传输到 1 层、1 层传输到 2 层和 2 层传输到 3 层时,这只是正常模型。但是当数据需要从 3 层传输到 4 层时,它需要从 GPU0 传输到 GPU1,这会带来通信开销。如果参与的 GPU 位于同一个计算节点(例如,同一台物理机器),则这种复制速度非常快,但如果 GPU 位于不同的计算节点(例如,多台机器),则通信开销可能会大得多。
然后,4 层到 5 层到 6 层到 7 层与正常模型一样,当第 7 层完成时,我们通常需要将数据发送回标签(label)所在的 0 层(或者将标签发送到最后一层)。现在可以计算损失,优化器可以开始工作了。
问题:
-
主要的缺陷以及为什么这个被称为“简单”MP,是因为除了一个 GPU 之外,其他 GPU 在任何给定时刻都处于空闲状态。因此,如果使用 4 个 GPU,这几乎等同于将单个 GPU 的内存量增加四倍,而忽略其余硬件。此外还有在设备之间复制数据的开销。因此,使用简单 MP,4 张 6GB 卡将能够容纳与 1 张 24GB 卡相同的大小,但后者将更快地完成训练,因为它没有数据复制开销。但是,如果你有 40GB 卡并且需要适应 45GB 模型,那么你可以使用 4 张 40GB 卡(但由于梯度和优化器状态,这几乎是不可能的);
-
共享嵌入shared embeddings可能需要在 GPU 之间来回复制。
流水线并行 (PP) 与简单的 MP 几乎相同,但它通过将传入批次分块为微批次并人为创建流水线来解决 GPU 空闲问题,从而允许不同的 GPU 同时参与计算过程。
来自 GPipe论文的插图上半部分显示了Naive MP,下半部分显示了 PP:
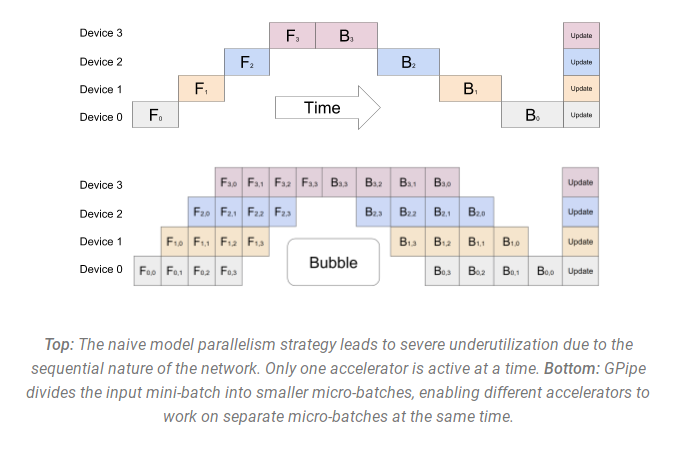
从下半部分中可以很容易地看出 PP 的死区较少 - 死区指GPU处于空闲状态,空闲部分被称为“气泡”。
图表的两部分都显示了 4 级并行性。也就是说,有 4 个 GPU 参与流水线。因此,有 4 个管道阶段 F0、F1、F2 和 F3 的前向路径,然后有 B3、B2、B1 和 B0 的反向后向路径。
PP 引入了一个新的超参数来调整,即块chunks,它定义了通过同一管道阶段按顺序发送多少个数据块。例如,上图下半部分中,你可以看到chunks = 4。GPU0 对块 0、1、2 和 3(F0,0、F0,1、F0,2、F0,3)执行相同的前向路径,然后等待其他 GPU 完成其工作,并且只有当它们的工作开始完成时,GPU0 才会再次开始工作,对块 3、2、1 和 0(B0,3、B0,2、B0,1、B0,0)执行后向路径。
注意到从概念上讲,这与梯度累积步骤 gradient accumulation steps (GAS) 是相同的概念。Pytorch 使用块chunks,而 DeepSpeed 引用与 GAS 相同的超参数。
由于存在块chunks,PP 引入了微批次micro-batches (MBS) 的概念。DP 将全局数据批次大小拆分为小批次,因此,如果 DP 度degree为 4,则全局批次大小 1024 将拆分为 4 个小批次,每个小批次 256 个 (1024/4)。如果块 chunks(或 GAS) 的数量为 32,我们最终得到的微批次大小为 8 (256/32)。每个管道阶段每次处理一个微批次。
要计算 DP + PP 设置的全局批处理大小,我们执行以下操作:\(mbs*chunks*dp_degree (8*32*4=1024)\)
让我们回到上图。
使用 chunks=1 时,你最终会得到Navie MP,这是非常低效的。使用非常大的 chunks 值时,你最终会得到非常小的微批次大小,这可能也不是非常高效。因此,必须进行实验才能找到导致 GPU 最高效率利用率的值。
虽然该图显示存在无法并行化的“死”时间气泡,因为最后的前向阶段必须等待后向阶段完成管道,但找到块的最佳值的目的是使所有参与的 GPU 实现高并发 GPU 利用率,从而最小化气泡的大小。
有两组解决方案 - 传统的管道 API 和更现代的解决方案,它们使最终用户的工作变得更加容易。
传统 Pipeline API 解决方案:
- PyTorch
- FairScale
- DeepSpeed
- Megatron-LM
现代解决方案:
- Varuna
- Sagemaker
传统 Pipeline API 解决方案存在的问题:
-
必须对模型进行大量修改,因为 Pipeline 要求将模块的正常流程重写为相同的 nn.Sequential 序列,这可能需要更改模型的设计。
-
目前 Pipeline API 非常受限。如果你在 Pipeline 的第一个阶段传递了一堆 python 变量,则必须找到解决方法。目前,管道接口 需要单个张量或张量元组作为唯一的输入和输出。这些张量必须具有批处理大小作为第一个维度,因为管道将把小批处理分成微批处理。此处正在讨论可能的改进 https://github.com/pytorch/pytorch/pull/50693
-
管道阶段级别的条件控制流是不可能的 - 例如,像 T5 这样的编码器-解码器模型需要特殊的解决方法来处理条件编码器阶段。
-
必须安排每一层,以便一个模型的输出成为另一个模型的输入。
我们尚未对 Varuna 和 SageMaker 进行实验,但他们的论文报告称,他们已经克服了上面提到的一系列问题,并且对用户模型的改动要求要小得多。
实现
- Pytorch(最初在 pytorch-1.8 中提供支持,并在 1.9 中逐步改进,在 1.10 中更是得到了进一步的改进)。
- FairScale
- DeepSpeed
- Megatron-LM 有一个内部实现 - 没有 API。
- Varuna
- SageMaker - 这是一个专有解决方案,只能在 AWS 上使用。
🤗 Transformers 状态:截至撰写本文时,所有模型均不支持全 PP。GPT2 和 T5 模型具有简单的 PP 支持。主要障碍是无法将模型转换为 nn.Sequential 并将所有输入都设为张量。这是因为当前模型包含许多使转换变得非常复杂的特性,需要将其删除才能实现这一点。
其他方法:
DeepSpeed、Varuna 和 SageMaker 使用交错管道的概念

在这里,通过优先考虑向后传递,气泡(空闲时间)被进一步最小化。
Varuna 进一步尝试通过使用模拟来发现最有效的调度,从而改进调度。
张量并行 Tensor Parallelism (TP)
在张量并行中,每个 GPU 仅处理张量的一部分,并且只为需要整个张量的操作聚合整个张量。
在本节中,我们使用 Megatron-LM 论文中的概念和图表:Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
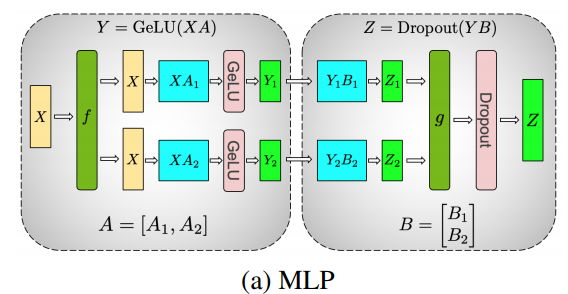
任何 Transformer 的主要构建块都是完全连接的 nn.Linear,后跟非线性激活 GeLU。
按照 Megatron 的论文符号,我们可以将其点积部分写为 Y = GeLU(XA),其中 X 和 Y 是输入和输出向量,A 是权重矩阵。
如果我们以矩阵形式查看计算,很容易看出矩阵乘法如何在多个 GPU 之间拆分:
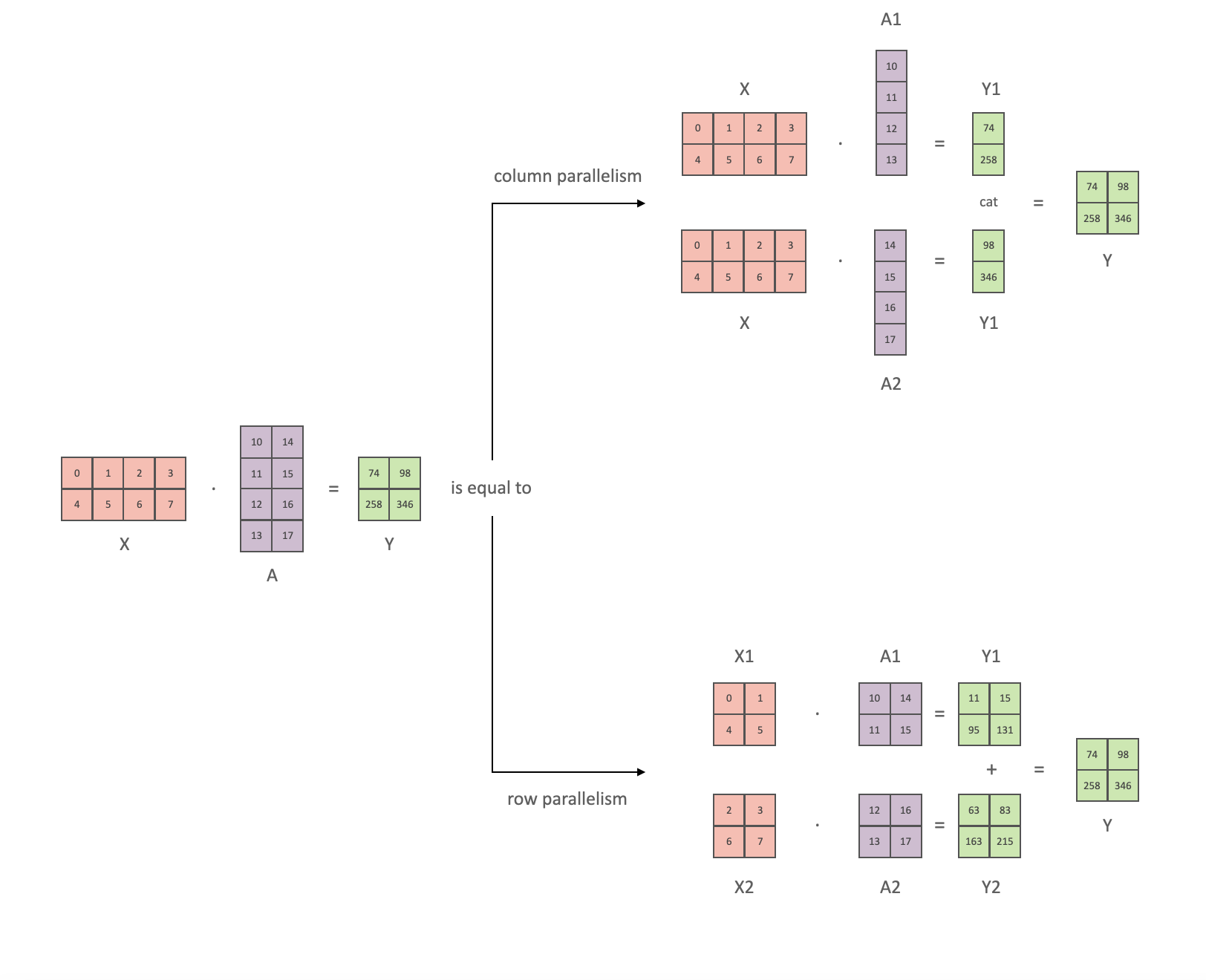
如果我们将权重矩阵 A 按列拆分到 N 个 GPU 上,并行执行矩阵乘法 XA_1 到 XA_n,那么我们将得到 N 个输出向量 Y_1、Y_2、…、Y_n,这些向量可以独立输入到 GeLU 中:
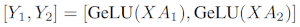
利用这一原理,我们可以更新任意深度的 MLP,而无需 GPU 之间进行任何同步,直到最后,我们才需要从碎片中重建输出向量。Megatron-LM 论文作者为此提供了一个有用的例子:
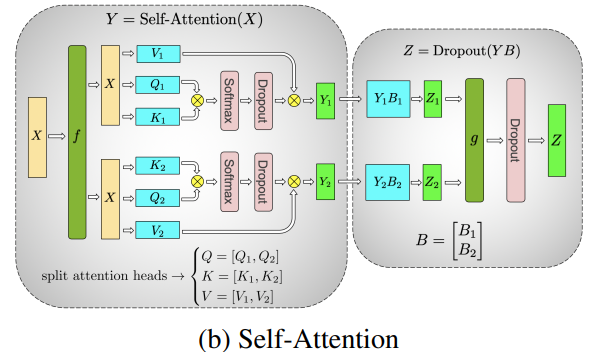
并行化多头注意力层更加简单,因为它们具有多个独立的头,本质上已经是并行的!
特别注意事项:TP 需要非常快的网络,因此不建议跨多个节点进行 TP。实际上,如果一个节点有 4 个 GPU,则最高 TP 度为 4。如果你需要 8 的 TP 度,则需要使用至少有 8 个 GPU 的节点。
本节基于原始的更详细的 TP 概述。作者:@anton-l。
SageMaker 将 TP 与 DP 结合起来,以实现更高效的处理。
其它名称:
DeepSpeed 称其为张量切片 tensor slicing
实现:
- Megatron-LM 有一个内部实现,特定于模型
- parallelformers(目前仅用于推理)
- SageMaker - 这是一个专有解决方案,只能在 AWS 上使用。
🤗 Transformers 状态:
- core:尚未在core中实现
- 但如果你想要推理,parallelformers 为我们的大多数模型提供了这种支持。因此,在核心中实现此功能之前,你可以使用它们。希望训练模式也能得到支持。
- Deepspeed-Inference 还支持我们的 BERT、GPT-2 和 GPT-Neo 模型的超快 CUDA 内核推理模式,更多信息请见此处
DP+PP
下图是来自 DeepSpeed 管道教程,演示了如何将 DP 与 PP 结合起来。
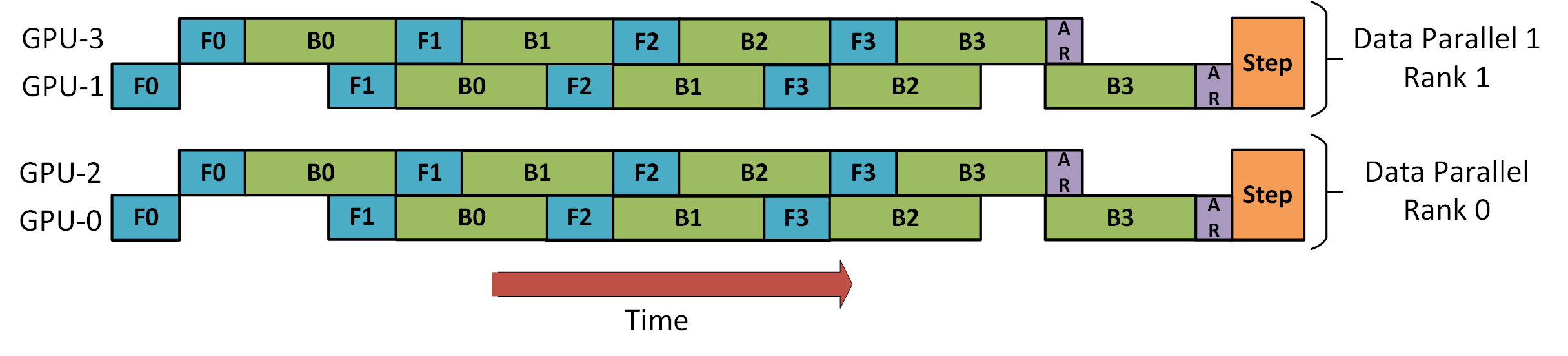
这里重要的是要看到 DP Rank 0 看不到 GPU2,而 DP Rank 1 看不到 GPU3。对于 DP 来说,只有 GPU 0 和 1,它向其中提供数据,就好像只有 2 个 GPU 一样。GPU0 使用 PP“秘密”将部分负载offload到 GPU2。而 GPU1 也通过寻求 GPU3 的帮助来做同样的事情。
由于每个维度至少需要 2 个 GPU,因此这里至少需要 4 个 GPU。
实现:
🤗 Transformers 状态:尚未实现
DP+PP+TP
为了实现更高效的训练,我们使用了 3D 并行,将 PP 与 TP 和 DP 相结合。如下图所示。
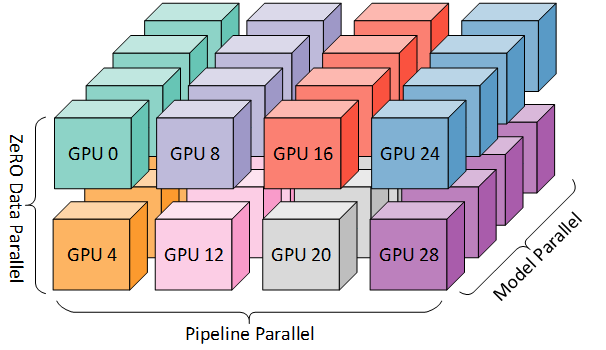
该图来自博客3D parallelism: Scaling to trillion-parameter models,这也是一篇值得一读的文章。
由于每个维度至少需要 2 个 GPU,因此这里至少需要 8 个 GPU。
实现:
- DeepSpeed - DeepSpeed 还包括一个更高效的 DP,他们称之为 ZeRO-DP。
- Megatron-LM
- Varuna
- SageMaker
🤗 Transformers 状态:尚未实现,因为我们没有 PP 和 TP。
DP+PP+TP+ZeRO
DeepSpeed 的主要功能之一是 ZeRO,它是 DP 的超可扩展。它已在 ZeRO Data Parallel 中讨论过。通常,它是一个独立的功能,不需要 PP 或 TP。但它可以与 PP 和 TP 结合使用。
当 ZeRO-DP 与 PP(和可选的 TP)结合时,它通常只启用 ZeRO 第 1 阶段(优化器分片)。
虽然理论上可以将 ZeRO 第 2 阶段(梯度分片)与流水线并行结合使用,但这会对性能产生不利影响。每个微批次都需要一个额外的 Reduce-Scatter 集合来在分片之前聚合梯度,这可能会增加大量的通信开销。根据流水线并行的性质,会使用较小的微批次,而重点是尝试平衡算术强度(微批次大小)和最小化流水线气泡(微批次数量)。因此,这些通信成本将受到影响。
此外,由于 PP,层数已经比正常情况少,因此内存节省不会很大。PP 已经将梯度大小减少至 1/PP,因此在此基础上的梯度分片节省不如纯 DP 显著。
出于同样的原因,ZeRO 第 3 阶段也不是一个好的选择——需要更多的节点间通信。
由于我们有 ZeRO,另一个好处是 ZeRO-Offload。由于这是第 1 阶段,因此优化器状态可以卸载到 CPU。
实现:
🤗 Transformers 状态:尚未实现,因为我们没有 PP 和 TP。
FlexFlow
FlexFlow 也以略有不同的方法解决了并行化问题。
论文:Beyond Data and Model Parallelism for Deep Neural Networks
它对样本-操作-属性-参数执行某种 4D 并行。
- 样本 = 数据并行(样本并行)
- 操作 = 将单个操作并行化为多个子操作
- 属性 = 数据并行(长度并行)
- 参数 = 模型并行(无论维度如何 - 水平或垂直)
举例:
- 样本
我们取 10 个序列长度为 512 的批次。如果我们按样本维度将它们并行化到 2 个设备中,我们将得到 10 x 512,即 5 x 2 x 512。
- 操作
如果我们执行layer normalization,我们首先计算 std标准差,然后计算mean平均值,然后我们可以规范化数据。运算符并行性允许并行计算 std 和mean。因此,如果我们按运算符维度将它们并行到 2 个设备(cuda:0、cuda:1),首先我们将输入数据复制到两个设备中,然后 cuda:0 计算 std,cuda:1 同时计算mean。
- 属性
我们有 10 个长度为 512 的批次。如果我们按属性维度将它们并行化到 2 个设备中,则 10 x 512 将等于 10 x 2 x 256。
- 参数
它与张量模型并行或navie分层模型并行类似。
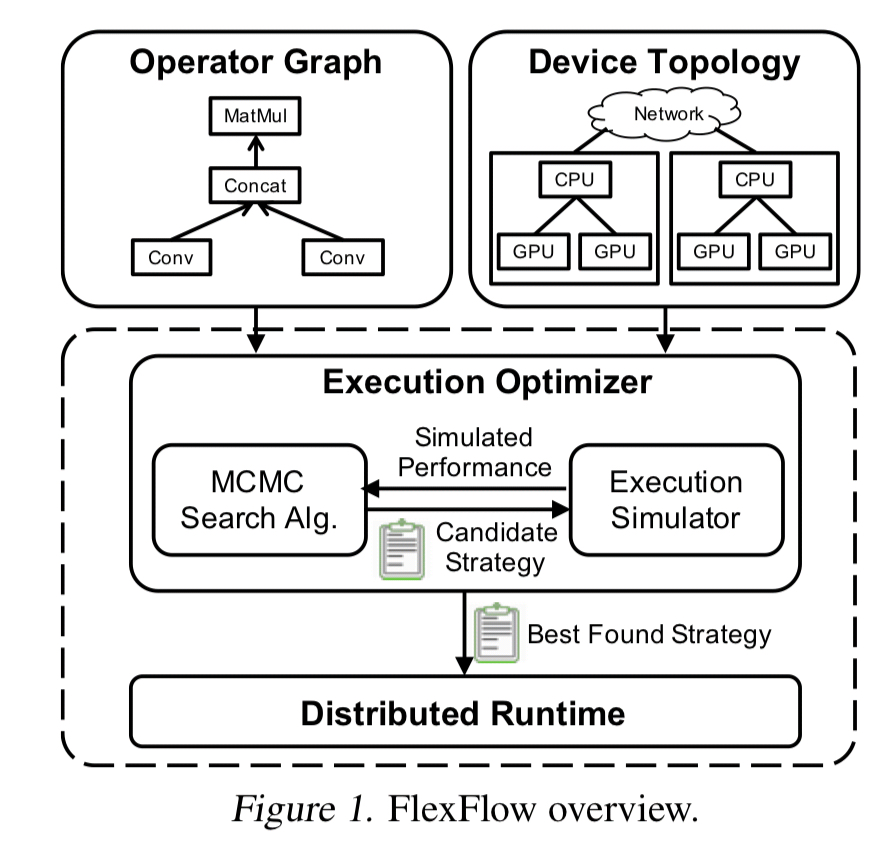
这个框架的重要性在于它占用的资源包括(1)GPU/TPU/CPU 与(2)RAM/DRAM 与(3)快速内部连接/慢速互连,并且它会自动优化所有这些资源,从而通过算法决定在哪里使用哪种并行化。
一个非常重要的方面是,FlexFlow 旨在针对具有静态和固定工作负载的模型优化 DNN 并行化,因为具有动态行为的模型可能更喜欢在迭代过程中使用不同的并行化策略。
因此,这个承诺非常有吸引力 - 它在所选集群上运行 30 分钟的模拟,并提出利用此特定环境的最佳策略。如果你添加/删除/替换任何部件,它将运行并重新优化该计划。然后你就可以训练了。不同的设置将有自己的自定义优化。
🤗 Transformers 状态:尚未集成。我们已经通过 transformers.utils.fx 实现了模型 FX 跟踪,这是 FlexFlow 的先决条件,因此需要有人弄清楚需要做什么才能使 FlexFlow 与我们的模型一起工作。
如何选择策略?
以下是何时使用并行策略的粗略概述。每个列表中的第一个通常更快。
单GPU
-
模型适合单个 GPU:
- 正常使用
- 模型不适合单个 GPU:
-
ZeRO + offload CPU 和可选的 NVMe
-
如上所述,如果最大层无法放入单个 GPU,则使用以内存为中心的平铺(详情见下文)
-
-
最大层不适合单个 GPU:
- ZeRO - 启用以内存为中心的平铺Memory Centric Tiling (MCT)。它允许通过自动拆分并按顺序执行来运行任意大的层。MCT 减少了 GPU 上活动的参数数量,但不会影响激活内存。由于这种需求在撰写本文时非常罕见,因此用户需要手动覆盖 torch.nn.Linear。
单节点多GPU
- 模型适合单个 GPU:
- DDP - Distributed DP
- ZeRO - 可能更快,也可能不快,具体取决于所用的情况和配置
- 模型不适合单个 GPU:
- PP
- ZeRO
- TP
- 有了 NVLINK 或 NVSwitch 的非常快速的节点内连接,这三者应该基本相当,如果没有这些,PP 将比 TP 或 ZeRO 更快。
- TP 的程度也可能有所不同。最好进行实验以找到特定设置中的赢家。
TP 几乎总是在单个节点内使用。即 TP 大小 <= 每个节点的 gpu。
- 最大层不适合单个 GPU:
- 如果不使用 ZeRO - 必须使用 TP,因为单独使用 PP 无法满足需求。
- 对于 ZeRO,请参见上面的“单 GPU”条目
多节点多GPU
- 当你拥有快速的节点间连接时:
- ZeRO - 因为它几乎不需要对模型进行任何修改
- PP+TP+DP - 通信较少,但需要对模型进行大量更改
- 当你拥有缓慢的节点间连接且 GPU 内存仍然不足时:
- DP+PP+TP+ZeRO-1
==============正文结束======================
参考
欢迎关注我的GitHub和微信公众号,来不及解释了,快上船!
仓库上有原始的Markdown文件,完全开源,欢迎大家Star和Fork!