LLMForEverybody
大模型分布式训练并行技术(四)张量并行
引言
在Transformer架构里,有两块主要的计算量较大的部分,一是Self-Attention,二是MLP。在前面的文章中,我们已经介绍了模型并行和数据并行,本文将介绍张量并行,这是一种更加细粒度的并行方式,可以进一步提高模型的训练效率。
张量并行使用了矩阵乘法可以并行计算的特性,将模型的参数划分为多个部分,每个部分在不同的设备上进行计算,最后将结果进行汇总。下面,我们分别看FFN和Self-Attention的张量并行实现。
MLP
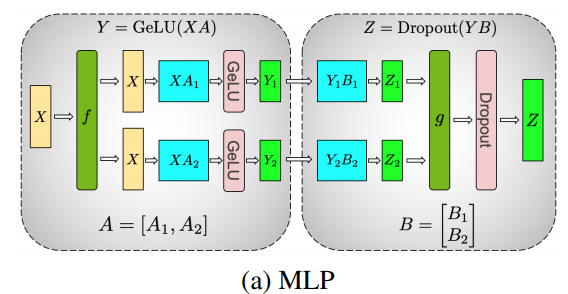
MLP的主要构建块都是完全连接的 nn.Linear,后跟非线性激活 GeLU。
按照 Megatron[2] 的论文符号,我们可以将其点积部分写为 Y = GeLU(XA),其中 X 和 Y 是输入和输出向量,A 是权重矩阵。
如果我们以矩阵形式查看计算,很容易看出矩阵乘法如何在多个 GPU 之间拆分:
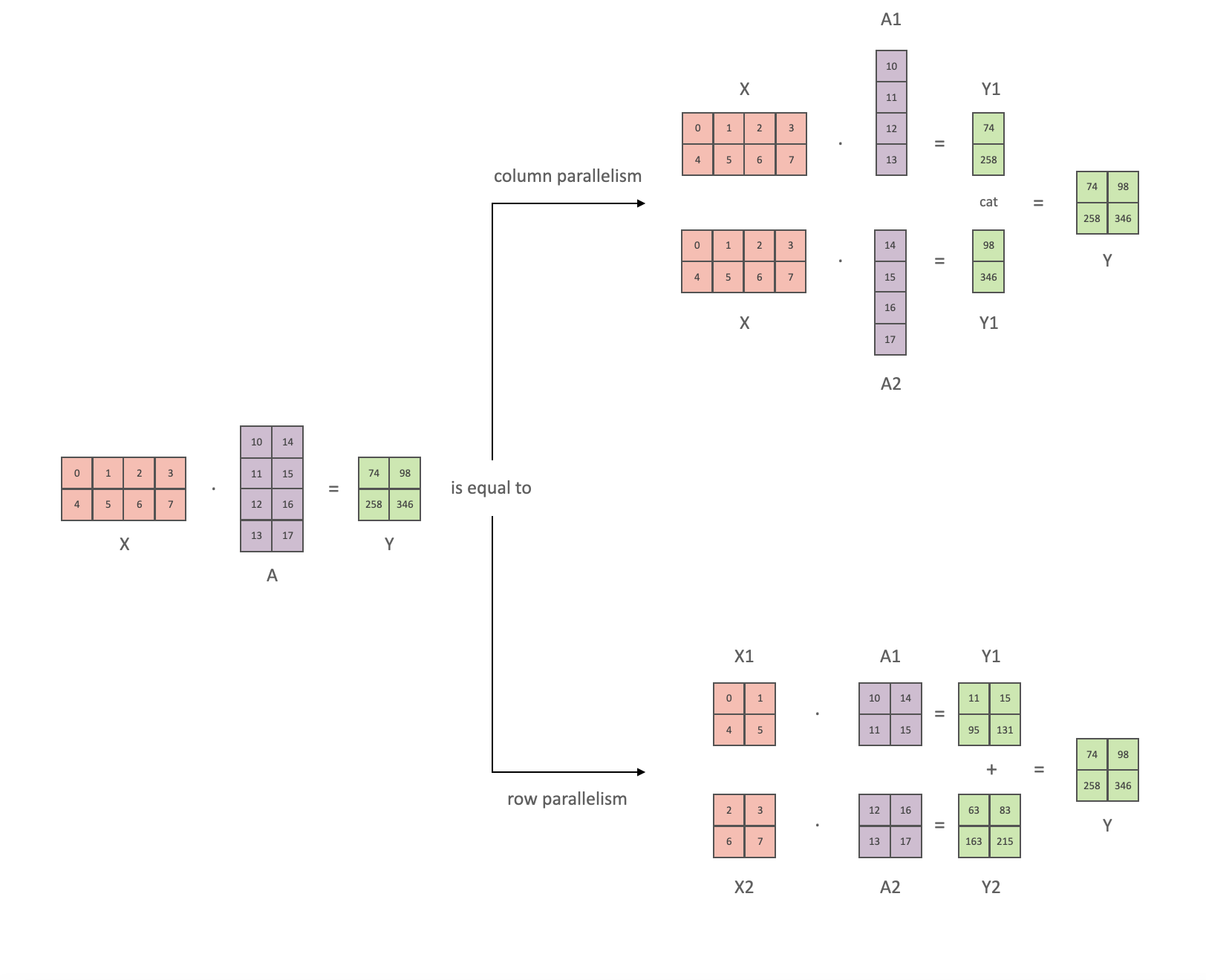
如果我们将权重矩阵 A 按列拆分到 N 个 GPU 上,并行执行矩阵乘法 XA_1 到 XA_n,那么我们将得到 N 个输出向量 Y_1、Y_2、…、Y_n,这些向量可以独立输入到 GeLU 中:
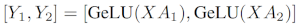
利用这一原理,我们可以更新任意深度的 MLP,而无需 GPU 之间进行任何同步,直到最后,我们才需要重建输出向量。
Megatron-LM 论文作者为此提供了一个有用的例子:
Self-Attention
Self-Attention 的张量并行更简单,因为self-attention天然的是多头注意力机制,可以将每个头的计算分配到不同的 GPU 上。
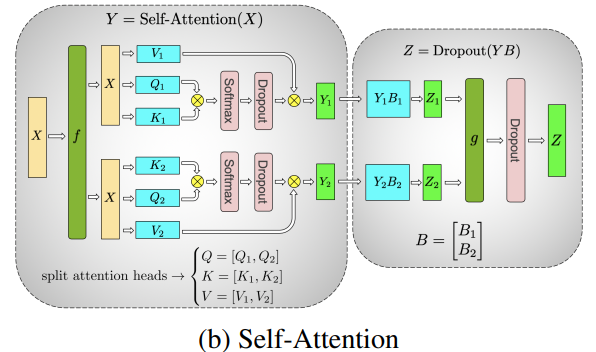
在上图中,我们可以用2个GPU并行的计算self-attention,其中每个GPU计算一个头的注意力机制。那原则上,有几个头就可以用几个GPU并行计算。
特别注意事项:TP 需要非常快的网络,因此不建议跨多个节点进行 TP。实际上,如果一个节点有 4 个 GPU,则最高 TP 度为 4。如果你需要 8 的 TP 度,则需要使用至少有 8 个 GPU 的节点。
下一篇我们看看混合并行。
参考
[2] Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
欢迎关注我的GitHub和微信公众号,来不及解释了,快上船!
仓库上有原始的Markdown文件,完全开源,欢迎大家Star和Fork!