LLMForEverybody
大模型分布式训练并行技术(三)流水线并行
引言
我们知道,大厂的高效在于大家都是流水线上的工人,每个人只负责自己的那一部分工作。在并行训练中,流水线并行是一种非常重要的技术,它可以将模型的训练过程分解为多个阶段,每个阶段由不同的设备负责,从而提高训练的效率。本文将介绍流水线并行的基本原理。
下文中流水线和管道都是pipeline的意思,是同一个概念。
朴素模型并行
朴素模型并行 Naive Model Parallelism 是指将模型层组分布在多个 GPU 上。每当数据进出时,会切换到与模型层相同的设备,其余部分保持不变。
例如,下图显示一个 8 层模型:

我们将其垂直切成两半,将 0-3 层放在 GPU0 上,将 4-7 层放在 GPU1 上。
现在,当数据从 0 层传输到 1 层、1 层传输到 2 层和 2 层传输到 3 层时,这只是正常模型。但是当数据需要从 3 层传输到 4 层时,它需要从 GPU0 传输到 GPU1,这会带来通信开销。如果参与的 GPU 位于同一个计算节点(例如,同一台物理机器),则这种复制速度非常快,但如果 GPU 位于不同的计算节点(例如,多台机器),则通信开销可能会大得多。
然后,4 层到 5 层到 6 层到 7 层与正常模型一样,当第 7 层完成时,我们通常需要将数据发送回标签(label)所在的 0 层(或者将标签发送到最后一层)。现在可以计算损失,优化器可以开始工作了。
缺点
-
除了一个 GPU 之外,其他 GPU 在任何给定时刻都处于空闲状态
-
shared embeddings可能需要在 GPU 之间来回复制
流水线并行
流水线并行 Pipeline Parallelism (PP) 与Naive MP 几乎相同,但它通过将传入批次分块为微批次并手动创建流水线来解决 GPU 空闲问题,从而允许不同的 GPU 同时参与计算过程。
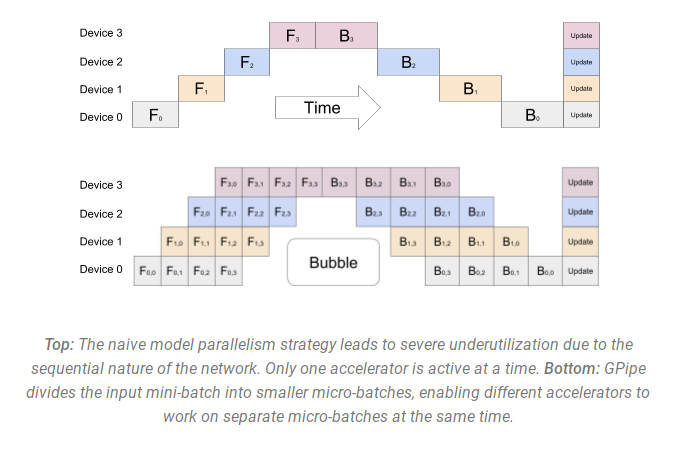
来自 GPipe论文的插图上半部分显示了Naive MP,下半部分显示了 PP:
Bubble
从下半部分中可以很容易地看出 PP 的死区较少 - 死区指GPU处于空闲状态,空闲部分被称为“bubble”(气泡)。
图的两部分都显示了 4 级并行性。也就是说,有 4 个 GPU 参与流水线。因此,有 4 个管道阶段 F0、F1、F2 和 F3 的前向路径,然后有 B3、B2、B1 和 B0 的后向路径。
PP 引入了一个新的超参数来调整,即块chunks,它定义了通过同一管道阶段按顺序发送多少个数据块。例如,上图下半部分中,你可以看到chunks = 4。GPU0 对块 0、1、2 和 3(F0,0、F0,1、F0,2、F0,3)执行相同的前向路径,然后等待其他 GPU 完成其工作,并且只有当它们的工作开始完成时,GPU0 才会再次开始工作,对块 3、2、1 和 0(B0,3、B0,2、B0,1、B0,0)执行后向路径。
使用 chunks=1 时,你最终会得到Navie MP,这是非常低效的。使用非常大的 chunks 值时,你最终会得到非常小的微批次大小,这可能也不是非常高效。因此,必须进行实验才能找到让 GPU 达到最高利用率的值。
虽然存在无法并行化的“死”时间气泡【这是因为最后的前向阶段必须等待后向阶段完成管道】,但找到块的最佳值的目的是使所有参与的 GPU 实现高并发,提高 GPU 利用率,从而最小化气泡的大小。
下一篇我们再看看张量并行。
参考
[2] Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models
欢迎关注我的GitHub和微信公众号,来不及解释了,快上船!
仓库上有原始的Markdown文件,完全开源,欢迎大家Star和Fork!